

Model retraining is a critical component of any robust MLOps stack, playing a fundamental role in ensuring the longevity and effectiveness of machine learning models. In this blog, we delve into the intricacies of model retraining, exploring its significance, various approaches, triggers, and best practices to empower organizations in mastering this essential component of MLOps.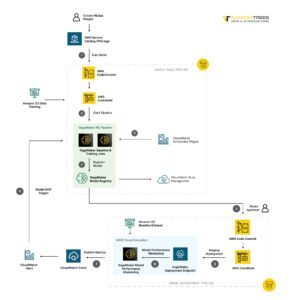
What is Model Retraining?
Model retraining, in essence, involves the creation of a new iteration of a machine learning model by rerunning the training pipeline with updated data. This iterative process ensures that the model remains aligned with the evolving patterns and dynamics present in the underlying data. Failure to engage in periodic retraining exposes models to the risk of diminishing performance, primarily attributed to data drift and concept drift.
Data drift occurs when the statistical properties of incoming data change over time. This shift can manifest in alterations to the distribution, variance, or other statistical characteristics of the data, thereby rendering the existing model less effective in capturing and generalizing patterns within the evolving data landscape. On the other hand, concept drift pertains to changes in the underlying relationships or mappings between input features and target variables. As real-world phenomena evolve, the relevance and significance of certain features may vary, necessitating adjustments in the model’s representation of these relationships.
Why Retrain Models?
Retraining models serves two fundamental purposes, both of which are instrumental in preserving the efficacy and relevance of machine learning systems:
1.Maintain Predictive Accuracy
As data drift and concept drift introduce variability and novelty into the data distribution, the predictive accuracy of machine learning models gradually diminishes. Periodic retraining acts as a corrective measure, recalibrating the model to better align with the evolving data landscape and thereby sustaining its predictive performance over time.
2.Incorporate New Data
By refreshing the training dataset through retraining, machine learning models gain exposure to the latest examples and patterns present in the data. This infusion of new data ensures that the model remains current and adaptable to emerging trends and phenomena, enhancing its capacity to generalize and make accurate predictions in real-world scenarios.
Retraining Approaches
When it comes to retraining models, organizations typically adopt one of two primary approaches:
Schedule-Based Retraining: In this approach, models are retrained at fixed intervals, such as weekly or monthly. While straightforward to implement, schedule-based retraining may overlook sudden or subtle changes in the data distribution, potentially leading to delayed adaptations and compromised model performance.
Trigger-Based Retraining: Trigger-based retraining relies on monitoring specific metrics or signals indicative of data drift or degradation in model performance. These triggers, which may include performance metrics like accuracy or F1 score, data distribution statistics, or prediction difference rates, serve as early warning systems, prompting retraining when predefined thresholds are exceeded. Although more complex to set up, trigger-based retraining offers greater responsiveness to changes in the data environment, enabling organizations to proactively adapt their models in line with evolving patterns and dynamics.
Retraining Triggers
Effective trigger-based retraining hinges on the careful selection and monitoring of relevant metrics or signals capable of detecting shifts or anomalies in the data distribution. By monitoring metrics that are responsive to the specific types of changes expected in the data, organizations can proactively detect situations where it’s necessary to retrain the model before any performance degradation occurs. Common triggers include performance metrics like accuracy, F1 score, or RMSE, alongside data distribution statistics and human-in-the-loop signals such as flagged predictions. By establishing clear thresholds for these metrics, organizations can automate the retraining process, ensuring timely interventions in response to changing data conditions.

Best Practices
To maximize the efficacy and scalability of model retraining within MLOps workflows, adherence to best practices is essential:
- Monitor Multiple Trigger Metrics: Relying on a diverse set of trigger metrics enhances the robustness of retraining mechanisms, enabling organizations to capture a broader spectrum of changes in the data environment.
- Retrain Asynchronously: Implementing asynchronous retraining processes minimizes delays and ensures that models remain synchronized with the latest data updates, thereby preserving their predictive accuracy and relevance.
- Continuous Testing in Pre-Production: By subjecting retrained models to continuous testing and validation in pre-production environments, organizations can identify and address potential issues or discrepancies before deploying models into production settings.
- Snapshot Training Dataset: Maintaining snapshots of the training dataset facilitates the reproducibility of retraining processes, enabling organizations to revisit and retrain older model versions if necessary.
- Validation Before Deployment: Prior to deploying retrained models into production, rigorous validation and testing protocols should be employed to verify their performance, stability, and generalization capabilities across diverse datasets and scenarios.
- Automation: Automating as much of the retraining process as possible streamlines operations and reduces the potential for human error, ultimately making retraining more efficient and accessible across the organization.
The Essential Role of Retraining
In summary, regularly updating and refining models through retraining is crucial in MLOps. It’s like a central piece holding together the accuracy and usefulness of machine learning models as they adapt to changing data patterns. By consistently incorporating the latest data and knowledge throughout the model’s lifecycle, organizations can keep their models flexible, robust, and suitable for real-world needs as they evolve.
Conclusion
Mastering model retraining in MLOps requires a holistic understanding of its underlying principles, methodologies, and best practices. By focusing on proactive and adaptable methods for model retraining, organizations can strengthen their machine learning systems, protecting them from the harmful impacts of changes in data patterns and underlying relationships. This ensures consistent performance, dependability, and applicability across various operational scenarios. As the landscape of MLOps continues to evolve, the imperative of effective model retraining will only grow in significance, underscoring its indispensable role in driving innovation, efficiency, and value creation in machine learning-driven enterprises.