

In the realm of Generative AI (Gen AI), understanding how different models perform under various conditions is crucial for selecting the best fit for your organization’s needs. AWS Bedrock offers robust tools to perform advanced and customized model evaluations, helping you compare and analyze different model performances and responses. This guide delves into the processes and modes available for conducting these evaluations, providing a foundational understanding.
The Importance of Model Evaluations
Model evaluations are pivotal in identifying the strengths and weaknesses of various models. By comparing models, you can uncover specific knowledge gaps and determine if a model aligns with your organization’s style and specific use cases. The evaluation process ensures that the chosen foundation model (FM) works well with your data, remains unbiased, and fits your organizational requirements.
Modes of Model Evaluation
AWS Bedrock supports three modes of running model evaluations:
- Automatic Evaluation
- Human: Bring Your Own Work Team
- Human: AWS Managed Work Team
Each mode offers different levels of customization and involvement of human judgment. Let’s explore these modes in more detail.
1. Automatic Evaluation
The automatic evaluation mode leverages AWS infrastructure to assess a model’s performance based on predefined or custom datasets. Here’s a breakdown of the steps involved:
Step-by-Step Process:
Select a Foundation Model: Choose the model you want to evaluate and configure its inference settings, such as randomness, diversity, length, and repetition.
Select a Task Type: Task types include
- General text generation – Used to generate text using NLP
- Text summarization – Used to perform summarization of text based upon prompts
- Question and answer – Used to provide answers based on text prompts
- Text classification – Used to classify text into different categories and classes based on the input data
Choose Metrics to Capture: Metrics could include toxicity, accuracy, and robustness.
Toxicity — which will assess the inclination to produce content that is harmful, offensive, or inappropriate.
Accuracy — This will evaluate the model’s capacity to provide factual information.
Robustness — This metric looks at how the model’s output is affected by minor changes that preserve semantic meaning.
Choose or Upload the Dataset: Use predefined datasets or your own to evaluate the model’s performance. Examples of predefined datasets include Gigaword, BoolQ, BOLD, RealToxicityPrompts, TREX, and WikiText2.
Bias in Open-ended Language Generation Dataset (BOLD) – Used to evaluate fairness across different domains, including: profession, gender, race, religious ideologies, and political ideologies.
RealToxicityPrompts – Used to evaluate toxicity in language
T-Rex: A Large Scale Alignment of Natural Language with Knowledge Base Triples (TREX) – Used to generate a subject, predicate, and an object linked by relation for NLP
WikiText2 – A HuggingFace dataset which contains prompts used for general text generation.

Figure 1: Evaluation metrics configuration screen in AWS Bedrock.
Specify Amazon S3 Location for Results: Define where the evaluation results will be stored on Amazon S3.
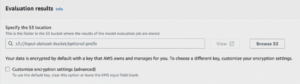
Figure 2: Evaluation results configuration screen in AWS Bedrock.
Specify IAM Role: Assign permissions to allow Bedrock to store results in the specified S3 location.
Inference and Scoring: Bedrock performs the evaluation and generates a scorecard stored in the S3 location.
View Results: Access and analyze the results from your S3 bucket.
2. Human: Bring Your Own Work Team
Human Evaluation Modes – Human evaluation modes introduce an element of human judgment, providing a more nuanced assessment of the model’s performance.
This mode allows you to utilize your own team to evaluate model responses. Here’s the process:
Step-by-Step Process –
Select Foundation Models: Evaluate up to two models simultaneously.
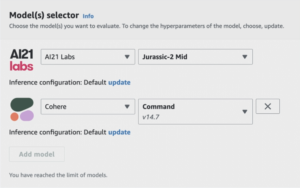
Figure 3: Model selector configuration for evaluation in AWS Bedrock.
Select a Task Type: An additional “Custom” task type is available for tailored evaluations.

Figure 4: Model evaluation task type configuration in AWS Bedrock
Define Evaluation Metrics: Depending on the selected ‘Task Type,’ you will need to specify metrics for the human team to evaluate and rate the model’s responses. A comparison between manual and automatic model options reveals a broader range of metrics available. Each metric chosen requires a description and a specified rating method for the human workforce. Options include a straightforward Thumbs up/down rating, a Likert scale — individual for nuanced approval ratings on a 5-point scale, an Ordinal rank for sequential ranking starting from 1, and a Likert scale — comparison to assess responses comparatively on a 5-point scale.
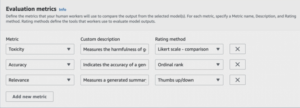
Figure 5: Evaluation metrics configuration screen in AWS Bedrock.
Specify Dataset Location: Point to the dataset stored on Amazon S3.
Specify Amazon S3 Location for Results: Define where to store the evaluation results.
Set Permissions: Assign roles for Bedrock and your workforce to access S3 locations.
Set Up Your Work Team: Configure your team using Amazon SageMaker GroundTruth, which manages user access and tasks.
Provide Instructions: Offer clear instructions to your workforce on evaluating tasks and metrics.
Submit the Job: Create and submit the evaluation job.
Workforce Completes Tasks: The workforce evaluates the prompts and submits results to S3.
View Results: Access and review the results from your S3 bucket.
3. Human: AWS Managed Work Team
In this mode, AWS provides a managed workforce to perform the evaluation. Here’s how it works:
Provide a Name for Your Evaluation: Assign a meaningful name to track the job.
Schedule a Consultation with AWS: Provide your contact details and discuss your evaluation requirements with AWS.
Liaise with AWS to Finalize Requirements: Confirm task types, datasets, metrics, and storage locations with AWS.
AWS handles the workforce management, ensuring that the evaluation is carried out by professionals with expertise in the required domains.
Conclusion
Running model evaluations in AWS Bedrock is a comprehensive process that allows you to understand and compare different models effectively. Whether you choose automatic evaluations for a more straightforward approach or human-involved evaluations for deeper insights, Bedrock provides the tools needed to ensure your chosen model aligns with your organization’s goals and data requirements. By following the steps outlined, you can gain a solid understanding of conducting model evaluations, paving the way for successful Gen AI applications.