
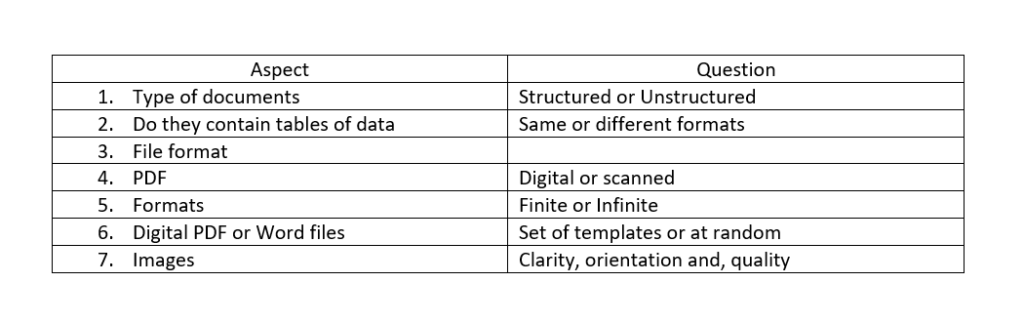
As for reliability on data increases, businesses seek top-notch solutions to facilitate data extraction from various documents. Building such solutions requires a trade-off between technical capabilities and business value. Organizations today seek to automate and scale up their process to save their time, effort, and money. There are various factors needed to be taken into consideration while devising an automated solution for this problem:
- Ensuring that the solution has advanced table extraction capabilities: A document with tables in varied formats makes it difficult to extract unless considered. Thus, the devised solution should consider this.
- Support for OCR integration: A document having a mix of text and images has its challenges. The solution should provide a unique dual processing method to tackle both text and pictures separately efficiently.
- Multi-lingual support: With the diverse set of languages present locally and globally, it becomes difficult to cater all if the defined corpus has only limited languages. Thus, the solution should have a more expansive language base.
- Implementing an API or a server with flexible output options: The end goal should not just be successful data extraction but also its appropriate deployment and integration to different tools and servers.
Few critical aspects are needed to be questioned, like:
Now that we have looked at both the ends of the process. Let’s see a few business use cases deploying data extraction.
Invoice Management

Consider yourself as a shipping department wherein you try to validate various vendors’ information, with documents having different formats. Your end goal is to extract data and validate buyer, shipment, and item-level information. The required solution should have a pre-trained model that is self-capable of understanding different invoices and documents to extract required data pairs.

Let’s say you are into “claims” business, and you want to automate the claims process by helping your customers to file claims more quickly. For this, you’ll need to capture certain aspects of email – e.g., the type of request, accident date, type of auto damage, the injury sustained. A solution for this type of problem would require learning and understanding the claims domains. One can also use sentiment analysis to identify the emotion of the customer.
Our Take on Data Extraction
Now that we have seen a few use cases of document extraction, let us take a tour of our product – Dcap. It leverages AI and machine learning to streamline and automate document data capture processing, enabling you to focus on higher-value tasks, increase speed and accuracy. It saves both time and money by eliminating data entry and requisite manual steps by 95%. It works with the document of any format without manual set up, auto validates the extracted data, and seamlessly integrates with corporate systems. It is self-enough to capture data from any document – Invoices, purchase order, shipping documents, contracts & agreements, Medical billing documents, HR forms and applications, ID cards & Passports, and Tax documents. Its notable features and benefits are:
- Simple to set up
- Competitive pricing – affordable is the key
- Scalable
- Can capture from a variety of document types
- Can integrate with any software – SaaS, private cloud, or managed services
- Intuitive user interface
- Reliable – processing over 5 million pages per month
- Support – available round the clock
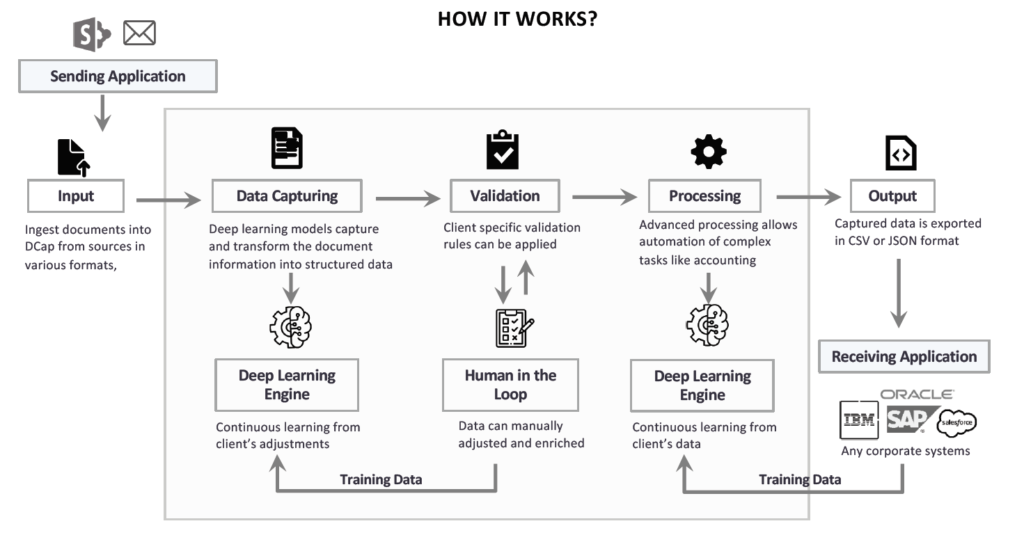
As a process, you need to input the document. Later it goes into the data capturing phase wherein requisite deep learning models capture and transform the information into a structured manner. Further, it goes to the validation stage. Here it can be molded as per the client’s specific rules and gets ingested into deep learning engines wherein continuous learning occurs as per the client’s modifications. The bridge between validation and deep learning engine gets bridged by a human in the loop who manually adjusts and enriches the process. After the validation phase, the process steps to the processing phase, wherein automation of complicated tasks facilitates output.