

Snowflake, the cloud data platform, has gained immense popularity for its flexibility, scalability, and ease of use. As organizations increasingly rely on Snowflake for their data warehousing needs, optimizing performance becomes paramount. One powerful feature that often goes underutilized is table clustering. In this article, we’ll explore the concept of table clustering and how it can significantly enhance the performance of your Snowflake data warehouse.
Understanding Table Clustering
Table clustering is a technique in Snowflake that involves physically organizing data in a table based on one or more columns. This arrangement helps to group similar data together, improving the efficiency of query processing. When queries are executed, Snowflake can leverage this clustering to access only the relevant data, minimizing the amount of data scanned and accelerating query performance.
The Benefits of Table Clustering
1. Improved Query Performance
By clustering your tables based on commonly queried columns, you reduce the amount of data that needs to be scanned during query execution. This can lead to significant improvements in query response times, ensuring that your analytics and reporting processes are faster and more efficient.
2. Cost Savings
Snowflake charges users based on the amount of data scanned during query execution. With table clustering, you can minimize the volume of data scanned, resulting in lower costs. By optimizing your data layout, you not only boost performance but also make your data warehouse more cost-effective.
3. Enhanced Concurrency
Efficient data clustering can improve the concurrency of your Snowflake environment. As queries become more streamlined, users can execute multiple queries simultaneously without compromising performance. This is particularly crucial in environments with heavy concurrent usage.
Best Practices for Table Clustering
1. Choose Appropriate Clustering Columns: Selecting the right columns for clustering is crucial. Identify columns frequently used in join conditions or where clauses to maximize the impact of clustering. Consider columns with high cardinality to distribute data evenly.
2. Monitor and Adjust: Regularly monitor query performance and adjust clustering configurations as needed. Over time, as data distributions change, revisiting clustering strategies can help maintain optimal performance.
3. Leverage Multi-Clustering: Snowflake allows for the definition of multiple clustering keys on a table. Utilize this feature to address different query patterns and enhance performance across a variety of use cases.
4. Cluster on Larger Tables: The benefits of clustering are more pronounced on larger tables. Focus on clustering larger tables where query optimization can have a significant impact on performance.
Case Study: Real-world Performance Gains
Let’s consider a real-world example where table clustering in Snowflake led to substantial performance gains. A retail company with a massive transactional dataset clustered its Inventory table based on Inventory_date and Inventory_item. This clustering strategy significantly accelerated reporting queries related to Inventory management, customer behaviour, and sales.
Clustering Performance Use Case
I’d like to emphasize the critical importance of clustering your tables, and what better way to drive this point home than by exploring a real-world scenario. We’re going to examine the differences in insert and select query profiles between tables that have been clustered and those that haven’t.
When it comes to setting up a clustered table in Snowflake, the process entails incorporating the CLUSTER BY clause during the table creation. To illustrate this, let’s walk through the creation of a clustered table based on dates.
For this particular use case, we’ll leverage one of Snowflake’s sample datasets.
TABLE_NAME: SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.inventory
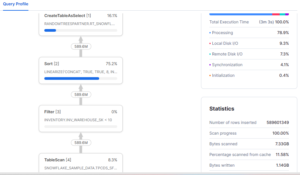
This table contains 1,965,337,830 records, table size is more than 7.33 GB. For exploration purpose, we are considering partial data where WAREHOUSE_ID less than 10. With the filtered dataset, we would be using 589,601,349 records which is around 1.14 GB. The Warehouse used is sized Small (X-Small).
Let’s create clustered and non-clustered tables.
Creating a Clustered Table
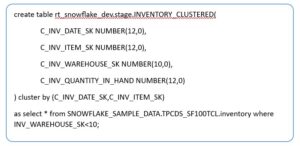
Query profile:
Creating a Non-Clustered Table
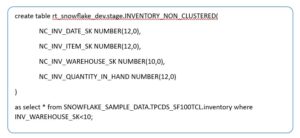
Now let’s see how select queries will be performed on clustered and non-clustered tables.
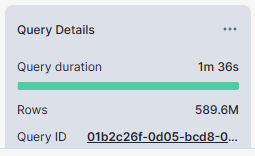
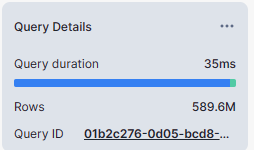
SELECT on non-clustered table:
select * from rt_snowflake_dev.stage.INVENTORY_NON_CLUSTERED;
select sum(NC_INV_QUANTITY_IN_HAND), avg(NC_INV_QUANTITY_IN_HAND)
from rt_snowflake_dev.stage.INVENTORY_NON_CLUSTERED
group by NC_INV_WAREHOUSE_SK;
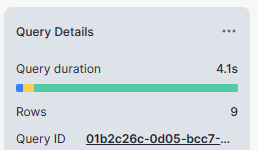
Select on clustered table:
select * from rt_snowflake_dev.stage.INVENTORY_CLUSTERED;
select sum(C_INV_QUANTITY_IN_HAND), avg(C_INV_QUANTITY_IN_HAND)
from rt_snowflake_dev.stage.INVENTORY_CLUSTERED
group by C_INV_WAREHOUSE_SK;
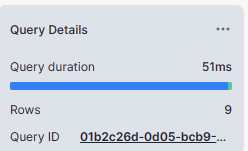
- Select on non-clustered tables took 4 seconds where as the same select on clustered table took less than 1 second.
Now Let’s compare DELETE statements:
Delete on non-clustered and clustered table:
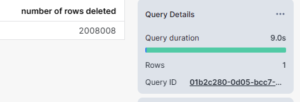
delete from rt_snowflake_dev.stage.INVENTORY_NON_CLUSTERED
where NC_INV_DATE_SK = 2451879;
delete from rt_snowflake_dev.stage.INVENTORY_CLUSTERED
where C_INV_DATE_SK = 2451879;

- The delete on non-clustered table took 9 seconds to delete 2008008 records but whereas the same delete statement in clustered table took 6 seconds.
Later we backfilled the same data to the table from original table.

Attention
Clustering keys are not intended for all tables due to the costs of initially clustering the data and maintaining the clustering. Clustering is optimal when either:
- You require the fastest possible response times, regardless of cost.
- Your improved query performance offsets the credits required to cluster and maintain the table.
Conclusion
In the era of big data, optimizing performance is a continuous challenge for organizations. Table clustering in Snowflake offers a potent solution to enhance query performance, reduce costs, and improve overall efficiency. By carefully selecting clustering columns, monitoring performance, and adapting to changing data distributions, organizations can unleash the full power of Snowflake’s data warehousing capabilities. Embracing table clustering is a strategic step towards building a high-performance data infrastructure that meets the demands of modern analytics.
Hope this article helped you optimize your Snowflake data warehouse.
Thank you for reading!