
Contents
- Approaches to modelling
- Hubs, Link and Satellite
- Concepts to Contemplate
Approaches to Modelling
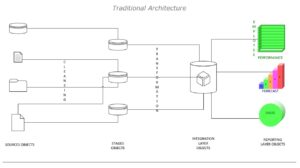
Traditional Approaches
The successful growth of any business depends on the choice of the right competitive advantage, and this will help sustainability. As a part of the competitive advantage business methodologies employ the use of technology and its precedence to a greater extent in today’s digital realm. Here choosing the right tools is a very integral part and its selection is crucial.
The choice of tools and adopting the right methodologies becomes the drive for any business and in this the selection on the database technologies is very crucial. Here the practice of data warehousing and warehouse system is very important and the use of right modelling techniques has become a very important factor in todays’ competitive world.
In this choice, Big Data will play an important role and its choice is also inevitably crucial in the Business Intelligence and related systems. The use of traditional 3 NF of Bill Inmon in the relational model and Ralf Kimball’s Star Schema design for the OLAP would be a bit outdated. So, here the argument on what to use and where to use become an important topic to be considered and here we can rather focus on some of the adaptable and sensitive models and we begin to consider the data vaults’ technique.
The enterprise data warehouse systems must be able to provide valuable and relevant information to business processes and downstream applications including user queries and reporting requirements. To do this the data driven approach that today’s company’s employ must be more adaptable and susceptible to change because if the EDW/BI systems fails to provide this, how will the change in information be addressed.?
Capturing the data and in today’s system the process of data capturing, data profiling, data cleansing and data transformation will be a huge picture as the data is just not data but Big data and this will be following all the characteristics of the big data paradigm.
Moreover, in today’s modelling and data driven approaches for systems has a lot of sub-lying concepts and techniques to be addressed and approached as per he required standards and in lieu of the same the need for addressing the administration, design, development, maintenance and support using various different and here we get into the complexity of the design.
The business needs are very dynamic and to address the same the enterprise warehouse needs to highly flexible in nature and to get the same fixed for each business domain and their answers the enterprise needs to be highly dependent on a system that is purely a mix of all the requirements and be in a position to answer them all. Kimball’s dimensional modelling or the star schema and Inmon’s normalized or snowflake needs to be overseen in a very high perspective to address the above all and for this we get into an approach of OLAP cubes where the data is viewed in different cubical perspectives. But this approach would also be more susceptible to cost and build factors.
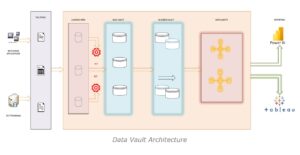
Data Vault Approach:
Data Vaults are nothing but a type of hybrid and new breed of approach to the modelling techniques which is more resilient and susceptible to changes. This resilient data base is capable of providing a platform to represent and save historical data for a captive analytical purpose. It has a wide capacity to collaborate 3NF and star schemas to minimize the change pattern, big, rather huge volumes, strange complexities and integrate drawback and bring out strong business model analysis efficiently.
Normally traditional warehouses found it very hard to implements an agile system of approach in building a traditional data/enterprise warehouse for their business needs. With the scale up of data vault approach, we could in simpler terms define or affirmative a data vault as an enterprise approach which is more agile in handling the changing data needs and build a data warehousing, analytics and data science requirements that need to run agile data warehouse projects where scalability, integration, development speed and business orientation are important.
So, what is a data vault model or modelling approach?
So, a data vault model forms the core for a data vault approach and is a data modeling design pattern used to build a data warehouse for organizations adopting enterprise-scalable analytics as and for its solutions. This type of architecture is more preferred in any enterprise where agile is more predominant and also suits any data lake paradigms.
This methodology has mainly three main core units or base components in its enterprise architecture, and they are being the HUB, LINK and the SATELLITE where the hubs represent the core of the business, the links represent the relationships between the bubs and the satellite represents the information about the hubs and relationships between them. Based on how these constructs are interconnected and related the model approach is categorized as standard; where each component is always constructed the same way to each other, simple; an easy-to-understand methodology which will be easy to deploy with a bit of familiarity and connected; where hubs will connect to links and satellites, links connect to hubs and satellites, and satellites connect to hubs or links dedicatedly.
Some simple benefits
As it is very clearly inferred from the above conceptual architecture a data vault technique is more scalable till and above pita bits of data, being ready for refactoring, more agile, can use familiar architecture principles using most available ETL/ELT codes and they can be generated at will. Auditability and traceability become more easier here facilitating business key usages and can accommodate almost a variety of data formats and standards also keeping in mind to make it easy for data profiling and cleansing methods. System loads and bottlenecks can be handled and attended more easier that before.
Though there are a lot of benefits for a data vault implementation to be deployed in an enterprise business, there are few drawback as well notably being, if data is to be loaded into a reporting system directly it becomes a question to ask as due to the interconnection and joins it may slow down the system to a considerable extent and in a situation where there is a sing source it is again a complex architecture which can be more effectively be achieved using a traditional system rather…
Hubs, Link and Satellite
A 3NF model is a default and acceptable model for a transactional system and a dimensional model is designed for a read process to happen from a warehouse, considering them to be the more effective model for data retrieval so far, and hence design the same using a method or approach which would facilitate them, arriving at a star schema. Here the model needed to be more agile to facilitate the consistency in the data retrieval but the data warehouse model stood to be more rigid. So, here the necessary for a more agile model is required and so a data vault model was designed which would fetch the solution using a 3NF and dimensional model together.
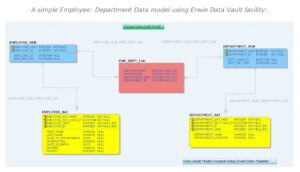
Having said this, the need to understand all the primary components of a data warehouse and then designing the data vault components is described.
3NF Forms
The first normal form ensures that each data field just has a single value, and would not compromise for holding composite value/multiple values. The second normal form ensures eliminating the repeating groups from the design and thus eliminating partial dependencies in the database relations if any. The 3NF is a form of design in which a design would be in the second normal form and also would not have any transitive dependencies. Thus, if a transitive dependency is avoided, it would be more efficient in gaining the possibilities of neglecting the redundancy caused due to any update anomalies, if any. This is also referred as the ER approach to modelling. In any 3NF a change to the parent with have a typical cascading erect to its children.
Note:
Transitive Dependency is a dependency in the data modelling and database design in which any non-prime attribute depends on other non-prime attributes instead of depending on the prime or primary key attributes that had been added in addition to the structure.
Dimensions
A dimension table is a table in any data model and database model designs which would normally contain the primary key, that would uniquely identify each row, and the other columns that refer to the attributes defined in the dimension of that dimensional model. The dimension table usually contains multiple columns and among them it would also have a primary key column. These table usually has fewer row compared to the next table the fact table.
Facts
A fact table is the next table in the dimensional model that usually hold the references to the dimension table and composes to be a table that contributes to providing numeric and additive information as a good practice in any dimensional modelling practice. These tables hold the foreign key subjective from their appropriate dimensions and are always qualified by measurements and aggregates as par of the entire business intelligence and analytics lifecycle. Also, they are normally characterized holding the composite key, any key which is formed using a subset of few other key and in any case, characterized such a way, is usually referred as fact table.
Grain
In any dimension table there would be available an attribute holding the level of detail and it is called as the grain of that dimension and it is always a good practice to design the model to hold the lowest level of grain possible. The facts may tend to talk at that level to which the dimensions were built as a good practice.
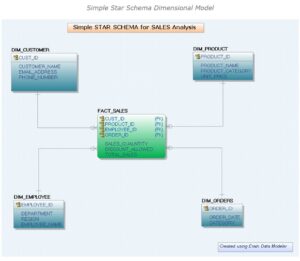
The above is a sample data model created on a star schema design whereby a star schema is a typical data warehousing design created with a centralized fact table and all the dimensions surrounding it resembling a typical star and this is a most preferred model as frequent data retrieval becomes easy, and when two stars are put together where the dimensions of one star communicates with another, it becomes a snowflake. Now it has been a clear inference that the 3NF would facilitate in good writing speed on the database and a dimensional model would in good reading or retrieval speeds from the database. There are other modelling enhancements depending on the requirement needs and other parameters, being, slowly changing designs, changing data captures etc. but no wonder they are agile they are good in reporting requirements.
So, in the above context if there is a requirement to add or extend any dimension it will be a very tedious process or task to be achieved and furthermore graining them is another challenge and to overlook the draw back where the model stands to be more rigid neglecting agility as well, the data vault concept becomes an alternative approach to overcome this massively introducing the concepts of Hubs, Links and Satellites.
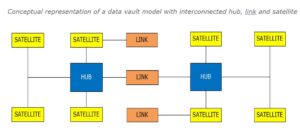
On a very high level, a hub would represent a business key and it gets linked to another hub with the help of a link and the same would be populated with the business contexts representing a satellite.
Hub
A Hub is a representation of the core business entity and as the name signifies it can be of any form of discussion examples being an employee, a customer, product, or a store. Though hubs talk about the main business entity they do not hold any details about that particular entity, instead they only contain the business keys along with few required key columns and the main include the hash key an unique identifier along with the load date/timestamp and the source record, a typical record from whence the data had come from.
Hubs typically pass on their integrity and facilitate a satellite to hold other attributes that would qualify the hub and one hub may be related to another or connected to another hub through links and cannot be directly connected to each other under any point of time.
Satellite
Satellites in data vault are the entities in context and provide descriptive information about the core business concepts the any hub would qualify. Any satellite can be connected to either a hub or a link and are subjective to their predecessors and contain the descriptive information about them and also would server to hold the time related information about them. From the above diagram as an example, an employee satellite contains details relating to the employee hub and a satellite respond to only one hub at any instance. The satellite normally contains a combination of the key corresponding to its hub and the load date as to maintain uniqueness and this may be understood comparing it to a typical surrogate key. This key help to main the consistency between each of the satellite and the hub it is connected with and this would help in data classification. Example: Employee’s Basic data and Employee’s Taxation data connected as two different satellites to the employee hub.
When a satellite is connected to a link it behaves like a link satellite and it is mainly concerned about the relationship patterns and they could have their own attribute as well. Satellites can also include the source meta information and they may also be subjective from the respective hubs.
Satellite has the main columns as to record the source, start and end dates and the combination of key which donates the uniqueness to the satellite. A hub can have more than one satellite. Each satellite may qualify the corresponding hub but may represent a different dimensional attribute in that context.
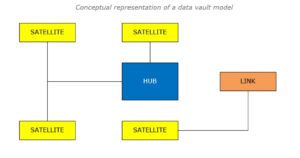
Conceptual representation of a data vault model with interconnected hub, link and satellite
Link
Links as the name signifies are the intersection of the business hubs and they store all necessary information pertaining to their integrity. These are the most dynamic objects as they dedicatedly change as and then when the business requirements change furthermore, they help in enhancing the model to a very easier extent in any case when the relationships change as objects get added or removed based on the needs. This feature of using and or having links makes the model easily flow with the lifecycle. Links may be connected to a hub or be connected to a satellite depending on the needs. Therefore, as the name signifies the link may hold the unique key and the date columns and the record sources and the key columns from either a hub or a satellite and it load type. Under any situation if a link gets repeatedly connected to its own hub more than once, it may possibly become a same as link and in a hierarchical relational definition it becomes a hierarchical link which is beyond the scope here and hubs can be interconnected only with the help of a link.
Concepts to Contemplate
Data Lake
So, first there came in a data base typically considered as a RDBMS data base and majorly used or designed to capture OLTP processes mainly used in places of live and real data characterized of having rows and columns and a very highly detailed data system moreover flexible. A data warehouse is a data base as such but a composite of data from many systems and mainly used for analytical processing which is why referred to as a OLAP data base and is characterized holding historical data which is often refreshed from the source system periodically, thereby providing a highly summarized system of data and is also highly rigid in design and is best planned ahead as it is not as flexible as a database. The data from many data bases are sent to the data warehouse through the ETL processes.
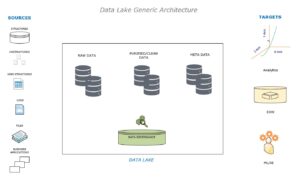
A data lake is one designed to capture any type of data, raw data; typically, structured, semi-structured or unstructured, moreover used mainly for processing large amounts of data for a typical machine learning or artificial intelligence systems, here referred to as ML and AI respectively. The major use case of having this is: it may be suitable for an analyzing purpose which post processes would require cleaning and profiling as the data is always raw and in which case it is not readily usable until otherwise and post that can be loaded into a database or a data warehouse for analysis or reporting. All of these data are collected by a process called as an ingestion process and this data which may not be required to be stored in a separate storage area called as a staging but is a recommended process to follow having a copy of all the source system data for further processing as mentioned earlier, the data cleansing, profiling, preparations like adding more features etc., post which is the ML model trainings. Here if there arises a need to modify the data pipeline, nothing but the data flow from the source to the stage, there is the capability of monitoring the flow processes and other data hold through the governance systems. Having said that, the governance system has all the meta data, and how on or more tables are related to each another and is defined using the governance policies a protocol how the business expects the data and how is meant to be used. These insights are now being presented to the real time system where they get analyzed and reported. The sources can also be on premises or cloud data as well and they in a typical environment would supply a business specific enterprise data warehouse EDW.
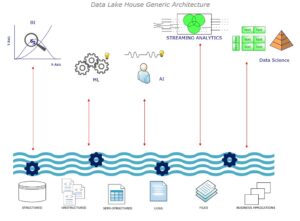
Data lakes are very effective being flexible and cost effective and an EDW serves in processing, speed, governance and structure, both serving as an edge in gaining the competitive advantages, but are rather hard to maintain and support having their own draw-backs. So, to overcome this the advantages from the data lakes and the EDW gets to be combined together in creating a new technical niche called the data lake house.
Lake houses help in loading loads of data in an effectively business specific storages and cost-effective way with load of governance layers feeding every business intelligence and high-performance ML workloads.
It is now clearly inferred that the cost factor is very much indeed a driving factor as data is now gained in large amount, derived from different sources and no wonder having a variety of formats and business had to spend huge costs in building a lake or warehouse, maintaining and supporting, governing and managing their lifecycles etc. Next comes the consumptions where data is not just consumed but consumed in a variety of forms like analytics, increase of AI in a variety of augmentations to get the insights. The last is a factor where business needs to modify the design and architecture to achieve the gaps getting filled in by employing appropriate pricing models, performance tools and techniques instead of binging to any stale design approaches. So, huge data, more users/consumers and very large consumption becomes the driving factor for getting an adaptable, not rigid and readily available systems.
D-a-a-S
Business today tries to stay on the competitive edge aligning themselves by modernizing their infrastructure, the cloud way or simply cloud computing, involves delivery of hosted services through the internet. Services can be IaaS, SaaS, PaaS etc., and the cloud-based system can be either private or public or hybrid. A cloud-based system that is dedicated for integration, management, storage and analytics is called as Data as a Service, DaaS. Though earlier handling massive data load over the internet was a challenge, today with many low-cost cloud-based solution DaaS offerings becomes more business specific and provides a reliable data system. DaaS involves supplying data from a wide variety of sources through API and on demand designed for simplifying data access. This data is further curated to deliver datasets or streams of data that can be consumed in a wide range of formats. DaaS includes a wide range of data management methodologies including data services, self-service analytics, data catalogs and data virtualization. This method of data democratization is critical for any business assuring to a greater extent, a huge opportunity to gain a competitive advantage with a more data-centric approach making them cost effective, lowering the data risks, data volume management, facilitate innovations a gain insight and above all agile decision making.
Cloud Data Warehouse
Any database that is stored as a managed service on a public cloud for achieving scalable BI and Analytics is a cloud data warehouse. This data is in a highly structured and unified in a cloud data warehouse and is be consumed for any business needs.
Key features that any cloud data warehouse must satisfy …
- Data integration and management is one of the important characteristics of a cloud data warehouse intended to make data readily available from ‘n’ number of sources and facilitate consumption patterns easily. Cloud based data warehouses stores data separately allowing access to it from anywhere at ease guaranteeing agility and flexibility.
- Storage becoming scalable storage in a cloud data warehouse so that any amount of data could be stored at will. Faster insights enabled with powerful computing capabilities, to deliver real-time cloud analytics and scalability offering immediate and dynamic storage as business needs grow gains advantages over cost.
- Columnar storage and in-memory caching are a very important concept for a cloud data warehouse employing MPP [Massively Parallel Processing], methodologies that help achieve data performances. MPP architectures provide high-performance queries on large data volumes consisting of many servers running in parallel to distribute processing and I/O [Input/Output] loads. Columnar data stores: MPP data warehouses are typically columnar stores which make them the most flexible and cost-effective solution for analytics to be achieved. Columnar databases are simple database systems in which data is stored and processed columns wise instead of rows wise as in any traditional system making aggregated queries to be executed more effectively.
- Cloud data warehouses are expected to enable data management, with efficient query processing, readily available backups and managements, securing and adapting proper methodologies including encryptions and access controls.
Automating the entire data warehouse process flow ensures high availability for ready to analyze data and makes them unique as to a traditional data warehouse gaining agility. Real time data ingestion, through automated workflows makes cloud data warehouse highly agile at the same time ensuring all other features are also satisfied. Without automation the movement of data into cloud data warehouse becomes requirements to preserve integrity and structure increases the chance of error or defects to be created, deferring the agility of the system. Few notable cloud data warehouse vendors are as listed below and each one having their own unique offerings …
- Amazon Redshift: First and widely adopted cloud data warehouse
- Microsoft Azure: Synapse Analytics
- Google Big-Query: Serverless solution
- Snowflake Cloud Data Warehouse: First sate of art multi-cloud data warehouse