
How I conduct Data Quality Assurance?
Introduction:
Quality Assurance is a very important aspect of Machine Learning/Data Engineering. ML Developers must make sure that the quality of data matches certain standards so that the models will perform the necessary tasks in the real world without fail. However, just checking to see if the quality seems good enough will not cut it in a very crucial field such as Machine Learning, which many consumers today depend on for certain tasks and needs. Therefore, the complexity of the whole process now leads to the question: how is Quality Assurance conducted?
Process of Data Labeling (aka ‘Annotations’):
The main Data Engineering must start first with Data Labeling. Data Labeling is the process of identifying specific raw data and adding label(s) to it so that the Machine Learning model can (learn to) identify it. This can also be known as ‘annotations’. Data Labeling is an important part of ML Engineering, especially in Computer Vision, Speech Recognition, and NLP (Natural Language Processing). The whole process begins receiving fresh, unlabeled data (also known as Data Sourcing). Following this, Data Engineers are asked to annotate certain sets of data. Now, this dataset sets a certain standard for the whole Machine Learning model to be trained and assessed. This dataset will be called “ground truth”. Next, another set of Data Engineers are given the same data that is unlabeled. They are then asked to label the same certain sets of data. However, the goal here should be to match the ground truth data set as much as possible. Typically, the Data Engineers working on this process of the ML model development will get a document containing certain rules and examples of what data is to be labeled. They will then be asked to label those sets of data based on the instructions. Followed by this will be (what I would like to say) the actual Quality Assurance. In my Claim Genius project (Computer Vision), the client supplied fresh, unlabeled images of damaged vehicles to RandomTrees/MouriTech Senior Data Engineers. These engineers then proceeded to produce the ground truth datasets by labeling the scratches, dents, tears, and glass breaks for the car in each image. Next, the same images were supplied to Junior Data Engineers. However, what’s different here is that they had to annotate the damages based on a certain set of instructions, and when annotating they had to make sure the annotations were precise enough to attempt to match the ground truth labels. Although I can predict that Senior Data Engineers were also expected to annotate the images based on the set of instructions, they had to use deeper analysis to produce the ground truth labels as this would be considered fresh data, which is very crucial for the model development. In this project as well, followed by these steps of Data Labeling was the actual Quality Assurance.

Quality Assurance, Overview of F-score calculation:
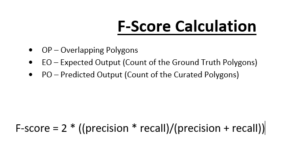
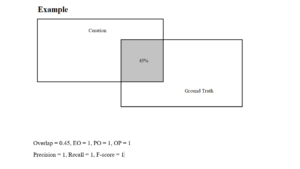
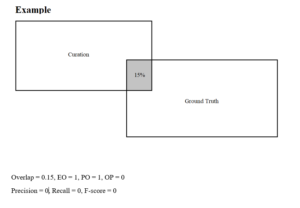
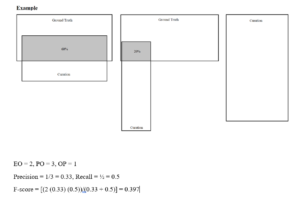
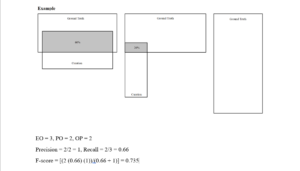
Well, what do I consider as actual Quality Assurance? I have already discussed the whole process of Data Labeling. Now, we must make sure that the labeling is accurate for the ML models to correctly learn and identify. In the Claim Genius project, the client sent me a Python script which was basically a calculator for the F-score. F-score is a measure of the model’s accuracy. It is also a way of combining the geometric mean of precision and recall of the model. Here, precision means the measure of the correctly identified positive cases from all the curated positive cases. Recall means the measure of the correctly identified positive cases from all the ground truth positive cases. The F-score must be above 0.25 and less than or equal to 1 for it to be valid. The higher (closer to 1) it is, the better accuracy the model has. However in the Claim Genius project, the F-score was calculated for each data annotation rather than the ML model as a whole. For example, each polygon that was drawn around each damage was matched with their intersecting counterparts from the ground truth data sets. Since we measured the intersection of each polygon, we calculated the F-score for each of them. Additionally, we checked to see if the precision and recall for each annotation was accurate, which is a very important factor in calculating the F-score.
My approach on Quality Assurance:
Developing an API
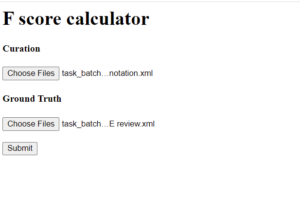
However, there is something interesting behind my calculation of the F-scores. Instead of using the given formula and calculating the F-score of each annotation by hand, I decided to develop an API using the Flask library in Python that will automate this process. The functionality of this API is that the user will upload the extracted xml files that contain the polygon annotation data of each image, which in return will download excel files that contain the F-scores. The F-scores will all be calculated in the back-end; between the time the user sends the xml files and receives the F-scores, that is when the client’s F-score calculator will be executed.
Docker Containerization
My main purpose for developing and deploying this API (I used Docker containerization to deploy this) was to automate this process for the clients so that they can use this to calculate the F-scores for their own data sets in a faster, more efficient manner.


About me:
I am a third year student at Texas A&M University, College Station, studying Computer Science. I am interested in learning more about new technologies and improving my skills on the go!
Here is my LinkedIn profile is here.